
After struggling with slow training times, I discovered the power of GPU tensors. Creating a list of tensors on the GPU dramatically boosted my model’s performance. The difference was night and day!
To create a list of tensors on the GPU in PyTorch, first check for GPU availability. Create an empty list. Generate tensors and move them to the GPU using .to(device). Append each tensor to the list. This optimizes GPU usage and speeds up training.
Unlock the power of your GPU with this guide on ‘How to create a list in pyTorch Gpu‘. Learn how to optimize your deep learning models for lightning-fast performance.
Understanding The GPU’s Role In Pytorch:
PyTorch leverages the power of GPUs to significantly speed up deep learning calculations. GPUs are specialized processors designed for parallel computing, allowing them to handle many calculations simultaneously.
By utilizing GPUs, PyTorch enables faster training of deep learning models, which is crucial for tasks like image recognition, natural language processing, and more. This translates to quicker development cycles and the ability to tackle more complex problems.
What Is The Purpose Of Creating A List Of Tensors On The GPU In Pytorch?
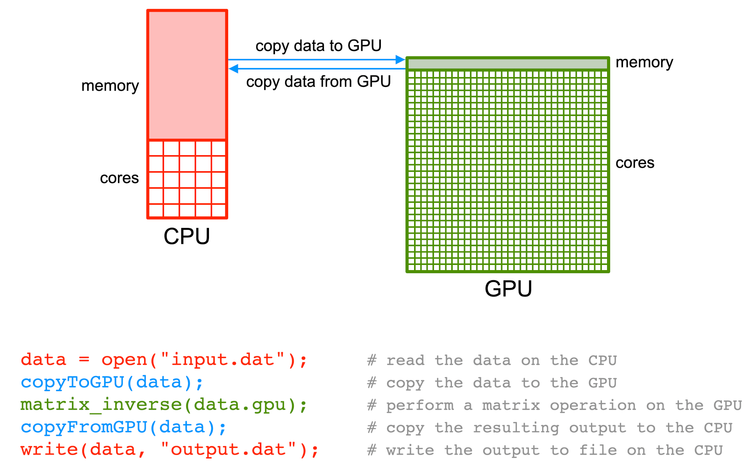
Creating a list of tensors on the GPU in PyTorch is essential for optimizing deep learning performance. By storing tensors directly in the GPU’s memory, you minimize the time-consuming process of transferring data back and forth between the CPU and GPU. This significantly speeds up computations, allowing for faster training and inference of your deep learning models.
Also Read: PS5 GPU Equivalent – Find Your GPU Match Now!
How Do I Check If My GPU Is Available For Pytorch?
To determine if your system has a compatible GPU for PyTorch, use the command torch.cuda.is_available(). This function will return True if a suitable GPU is detected and False otherwise. This simple check allows you to ensure your code can effectively utilize GPU acceleration for faster training and inference of your deep learning models.
How To Make A Pytorch Distribution On GPU?
To distribute a PyTorch model across multiple GPUs, you can utilize techniques like data parallelism or model parallelism. Data parallelism replicates the model on each GPU and distributes data across them. PyTorch provides torch.nn.DataParallel for easy implementation of this approach.
How To Create A List In Pytorch GPU?
1. Check GPU Availability:
- Before creating any GPU tensors, verify if a compatible GPU is available on your system.
- Use
torch.cuda.is_available(). If this returnsTrue, a GPU is detected, and you can proceed with GPU operations.
2. Create an Empty List:
- Initialize an empty Python list to store the tensors you will create on the GPU.
- For example:
gpu_list = []
3. Create Tensors on the GPU:
- Create PyTorch tensors using functions like
torch.randn(), torch.zeros(), etc. - Move these tensors to the GPU’s memory using
.to(device), wheredeviceistorch.device("cuda")if a GPU is available. - Example:
tensor = torch.randn(2, 3).to(device)
4. Append Tensors to the List:
- Use the
append()method of the list to add each GPU tensor to the list. - For example:
gpu_list.append(tensor)
5. Verify Tensor Location (Optional):
- To confirm that the tensors are indeed residing on the GPU, you can check their device attribute.
- Example:
print(gpu_list[0].device)
Convert List Of Tensors To Tensor Pytorch:
1. Understanding the Need:
- Often, you might have a list of individual PyTorch tensors.
- To efficiently process these tensors together, it’s often beneficial to combine them into a single, larger tensor.
2. Using torch.stack():
torch.stack()is the primary method for combining a list of tensors into a single tensor.- It concatenates the tensors along a new dimension.
Example:
import torchtensor_list = [torch.randn(2, 3) for _ in range(3)] stacked_tensor = torch.stack(tensor_list, dim=0)
- This code creates a list of 3 random tensors, each of size (2, 3).
torch.stack()then combines these tensors along a new dimension (dimension 0), resulting in a tensor of size (3, 2, 3).
3. Key Considerations:
- Tensor Shapes: Ensure that all tensors in the list have the same shape except for the dimension along which you are stacking.
- Data Type: All tensors in the list must have the same data type (e.g.,
torch.float32).
By using torch.stack(), you can efficiently combine a list of tensors into a single tensor for further processing within your PyTorch models.
How Do I Convert A Pytorch Tensor To A List?
You can convert a PyTorch tensor to a Python list using the tolist() method. This method efficiently transforms the tensor’s data into a nested list structure, mirroring the original tensor’s dimensions.
For example, a 2D tensor will be converted into a list of lists. This conversion is useful when you need to interact with the tensor data outside of the PyTorch framework or for tasks that are more easily performed with Python lists.
Also Read: Is 60 Degrees Celsius Hot For A GPU – Keep Your GPU Cool!
How To Use 2 GPU Pytorch?
To utilize two GPUs in PyTorch, you can employ the torch.nn.DataParallel class. This approach distributes the model’s computation across the available GPUs, enabling faster training. You wrap your model instance with DataParallel, specifying the desired GPU IDs. The framework then handles the distribution of data and model operations across the selected GPUs.
Example:
import torch.nn as nn
model = YourModel()
model = nn.DataParallel(model, device_ids=[0, 1]) # Use GPUs 0 and 1This code snippet wraps your YourModel instance with DataParallel, instructing PyTorch to utilize GPUs with IDs 0 and 1 for parallel processing.
Note: Ensure you have installed the CUDA version of PyTorch and have compatible GPUs available in your system.
How To Check Number Of GPU Pytorch?
You can determine the number of available GPUs in your system for PyTorch using the torch.cuda.device_count() function. This function returns an integer representing the count of accessible GPUs.
import torch
num_gpus = torch.cuda.device_count()
print(f"Number of GPUs available: {num_gpus}") This code snippet will print the number of GPUs that PyTorch can detect and utilize for your deep learning tasks.
How To Convert A List Of CUDA Tensors To A List Of CPU Tensors?
To convert a list of CUDA tensors (tensors residing on the GPU) to a list of CPU tensors, you can efficiently use a list comprehension in conjunction with the .cpu() method.
Here’s how:
1. Iterate through the list:
- Create a new list using a list comprehension.
- Inside the comprehension, iterate through each CUDA tensor in the original list.
2. Move Each Tensor To CPU:
For each tensor, use the .cpu() method to move it from the GPU’s memory to the CPU’s memory.
Example:
import torch
# Assuming you have a list of CUDA tensors
gpu_tensor_list = [torch.randn(2, 3).cuda() for _ in range(3)]
# Convert to a list of CPU tensors
cpu_tensor_list = [tensor.cpu() for tensor in gpu_tensor_list] This concise approach effectively converts the entire list of CUDA tensors to CPU tensors, enabling you to work with them on the CPU if needed.
How Do I Create An Empty List To Store GPU Tensors?
To create an empty list in PyTorch to store tensors that will reside on the GPU, you simply use the standard Python syntax for creating an empty list: gpu_list = []. This creates an empty list object that you can then populate with PyTorch tensors that have been moved to the GPU using the .to(device) method where device is set to torch.device("cuda").
How Do I Create A Tensor On The GPU?
To create a tensor that resides directly on the GPU’s memory in PyTorch, you first create a tensor using functions like torch.randn(), torch.zeros(), or torch.ones(). Then, you use the .to(device) method to explicitly move the tensor to the GPU’s memory. Here, device should be set to torch.device("cuda") if a compatible GPU is available.
How Do I Append A Tensor To The List?
To add a tensor to a list in PyTorch, you use the append() method. This method is a standard Python list operation. After creating a tensor and moving it to the GPU using .to(device), simply use list_name.append(tensor) to add that tensor to your list of GPU tensors. This allows you to efficiently store and manage multiple tensors within the GPU’s memory for your deep learning tasks.
Also Read: Is 99% GPU Usage Bad? – Use Monitoring Tools Regularly!
What Are The Benefits Of Using A List Of GPU Tensors?
Using lists of GPU tensors offers several key advantages:
- Reduced Data Transfer: Minimizes the time-consuming process of moving data between the CPU and GPU, a major bottleneck in performance.
- Optimized GPU Utilization: Keeps data readily accessible for processing within the GPU’s memory, maximizing the efficiency of GPU resources.
- Faster Training and Inference: Enables significantly faster execution of deep learning models due to reduced data transfer and optimized GPU usage.
How Do I Access Elements In The List Of GPU Tensors?
You can access individual tensors within the list using standard Python list indexing, such as gpu_list[0] to access the first tensor in the list. This allows you to easily work with specific tensors within your list for further processing or analysis.
Can I Perform Operations Directly On Tensors Within The GPU List?
Yes, you can perform operations directly on tensors residing within the GPU list. This is a key advantage of keeping tensors on the GPU, as it allows for efficient and fast computations without the overhead of transferring data back and forth between the CPU and GPU. This significantly speeds up training and inference processes in your deep learning models.
What Are Some Best Practices For Creating And Using GPU Tensor Lists?
To optimize the use of GPU tensor lists in PyTorch, consider these best practices:
- Minimize Data Transfers: Reduce the number of times you move data between the CPU and GPU.
- Transfer Large Chunks: Transfer large amounts of data in one go to minimize overhead.
- Be Mindful of Memory: Avoid creating excessively large lists that might exceed the available GPU memory.
- Utilize GPU-Accelerated Libraries: Leverage libraries like cuBLAS and cuDNN for optimized operations on GPU tensors.
Where Can I Find More Advanced Examples And Tutorials?
For more advanced examples and tutorials on creating and utilizing lists of GPU tensors in PyTorch, refer to the official PyTorch documentation. You can also explore a wealth of resources online, including tutorials, blog posts, and community forums dedicated to PyTorch.
These resources provide in-depth guidance and advanced techniques to help you master GPU-accelerated deep learning in PyTorch.
Also Read: How To Clear GPU Memory – Solve GPU Memory Problems!
FAQs:
1. Can I Create A List Of Different Tensor Shapes On The GPU?
Absolutely! You can create a list containing tensors with varying shapes and sizes on the GPU. This flexibility is crucial for handling diverse data structures in deep learning models.
2. Is It Possible To Create Nested Lists Of GPU Tensors?
Yes, you can create nested lists (lists within lists) of tensors on the GPU. This can be useful for organizing complex data structures, such as hierarchical models or sequences.
3. Can I Perform In-Place Operations On Tensors Within The GPU List?
Yes, you can perform in-place operations directly on the tensors within the GPU list. This can improve memory efficiency and performance. For example:
tensor = torch.randn(2, 3).to(device)
gpu_list.append(tensor)
gpu_list[0].add_(1) # In-place addition 4. How Can I Efficiently Copy A List Of GPU Tensors?
You can create a shallow copy using gpu_list_copy = gpu_list.copy(). This creates a new list object but still references the original tensors.
For a deep copy, you need to create new tensors:
gpu_list_copy = [tensor.clone().detach() for tensor in gpu_list]5. What Are The Implications Of Using Lists Of GPU Tensors For Memory Management?
- Be mindful of GPU memory usage, especially when dealing with large tensors or numerous tensors in the list.
- Consider strategies like memory pinning to reduce data transfer latency between CPU and GPU.
- Efficiently clear the list when no longer needed to avoid memory leaks.
6. Can I Use List Comprehensions To Efficiently Create And Manipulate Lists Of GPU Tensors?
Yes, list comprehensions provide a concise and efficient way to create and manipulate lists of GPU tensors.
gpu_tensor_list = [torch.randn(2, 3).to(device) for _ in range(5)]7. How Can I Debug Issues Related To Lists Of GPU Tensors?
- Use print statements to inspect the values and shapes of tensors within the list.
- Utilize PyTorch’s debugging tools to identify and resolve issues.
- Carefully check for errors related to GPU memory allocation and data transfer.
Final Words:
In summary, by effectively creating and utilizing lists of GPU tensors in PyTorch, you can significantly accelerate your deep learning models. This optimization minimizes data transfer between the CPU and GPU, maximizing GPU utilization and leading to faster training times. This allows you to tackle more complex projects and achieve faster results in your deep learning endeavors.
Related Posts:
- Red Light On GPU When Pc Is Off – Don’t Panic, Check This Now
- NVIDIA Overlay Says GPU VRAM Clocked At 9501 MHz – Compete Guide 2024!
- Do You Need GPU For Data Science – Find Out Now!
- What Is A Good GPU Clock Speed MHz – Complete Guide 2025!